Movie Recommendation System
See the full report here: Movie Recommendation System
For this project, our goal was to use a large dataset of the ratings that 943 users have given to 1682 movies to build a recommendation system to help guess which movies a user will like.
Input: The input to our prediction system is a pair i,j, which denotes a specific user id (denoted by index i, one of 943 possibilities) and movie id (denoted by index j, one of 1682 possibilities).
Output: The output of our predictor is a scalar rating ŷ. For each possible user-movie pair i,j, we’d like ŷ to be as close as possible to the “real” 5-star rating y that the user i gave the movie j. We can represent any five star rating with an integer in {1,2,3,4,5}: a rating of 1 is the worst possible, a rating of 5 is the best.
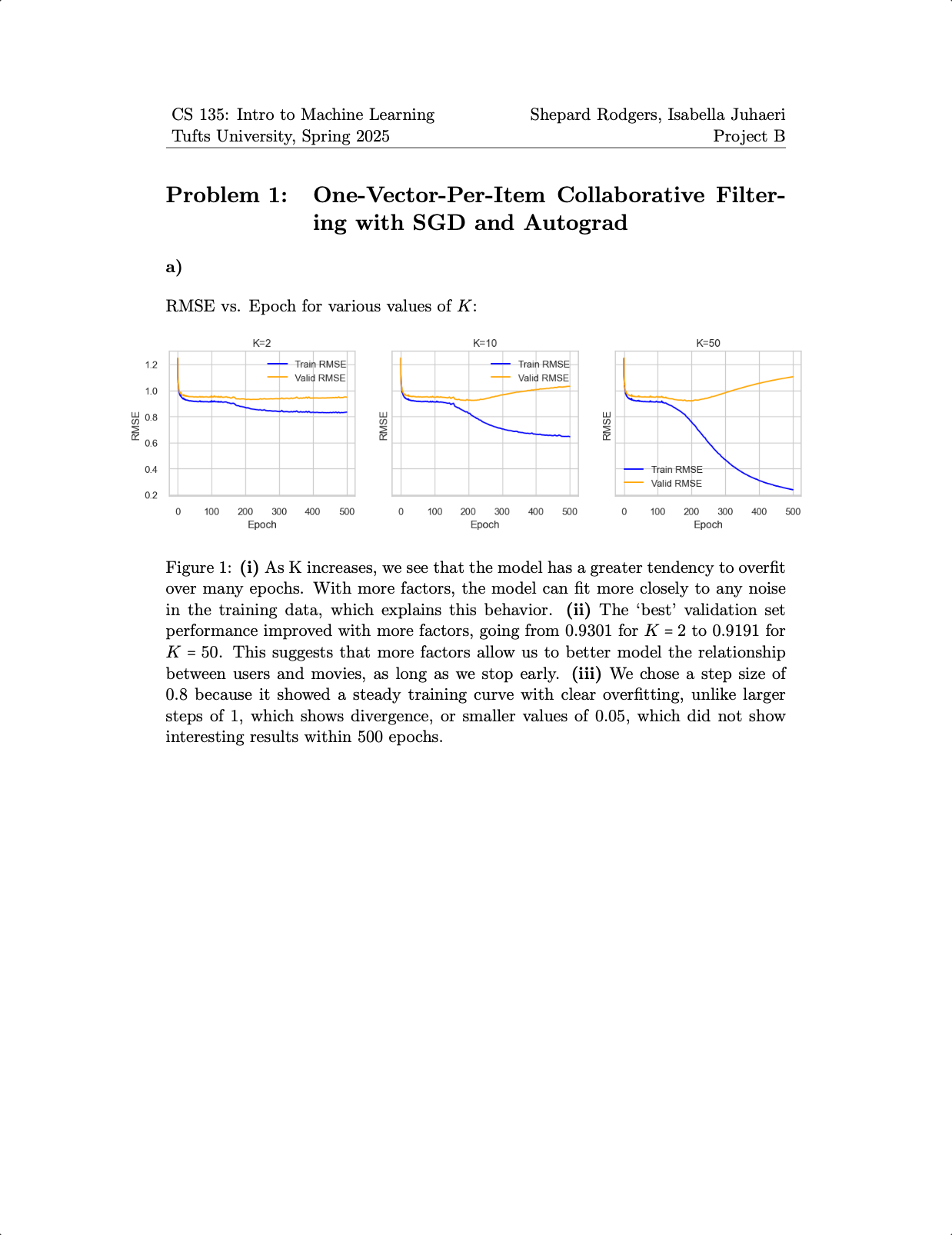
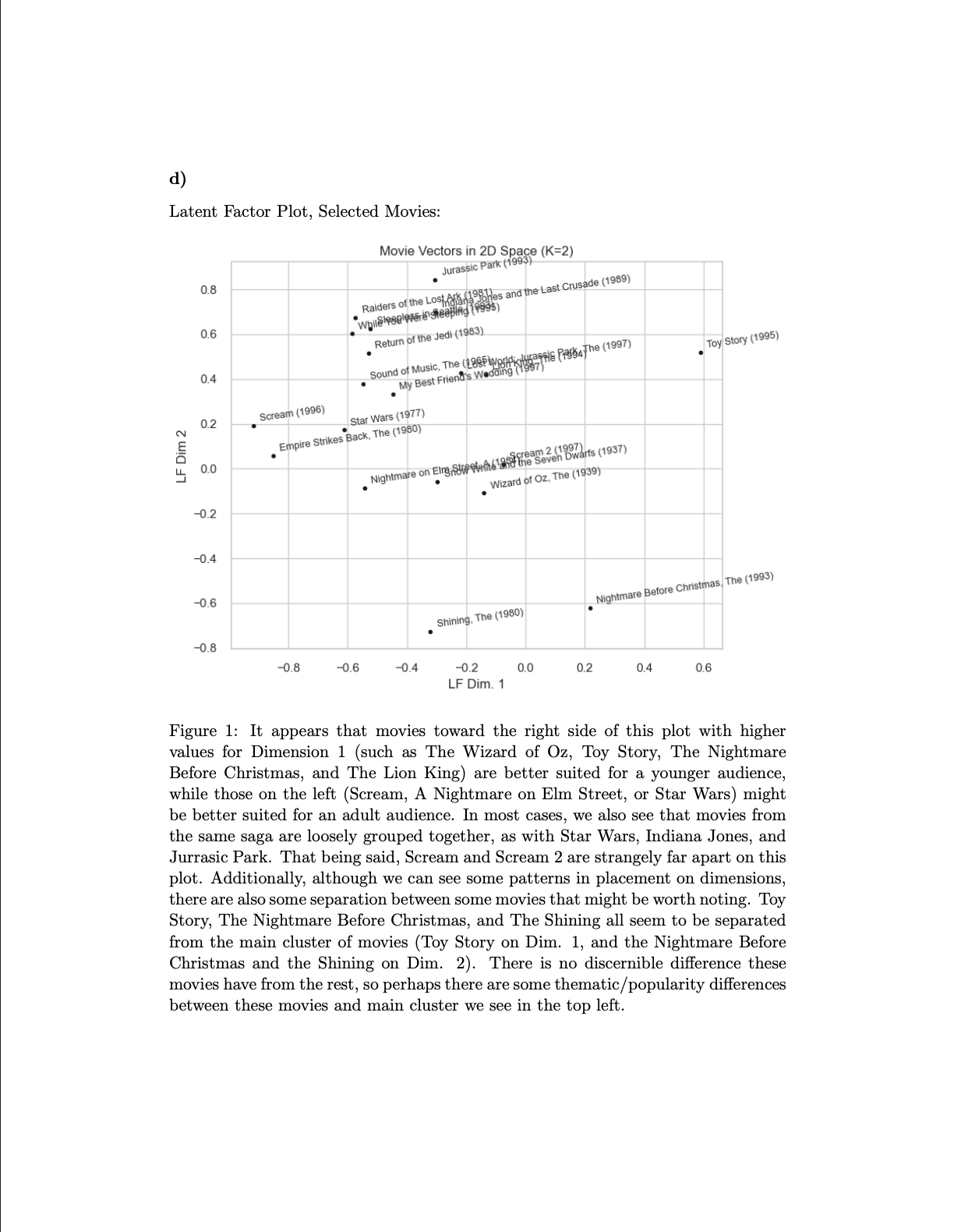
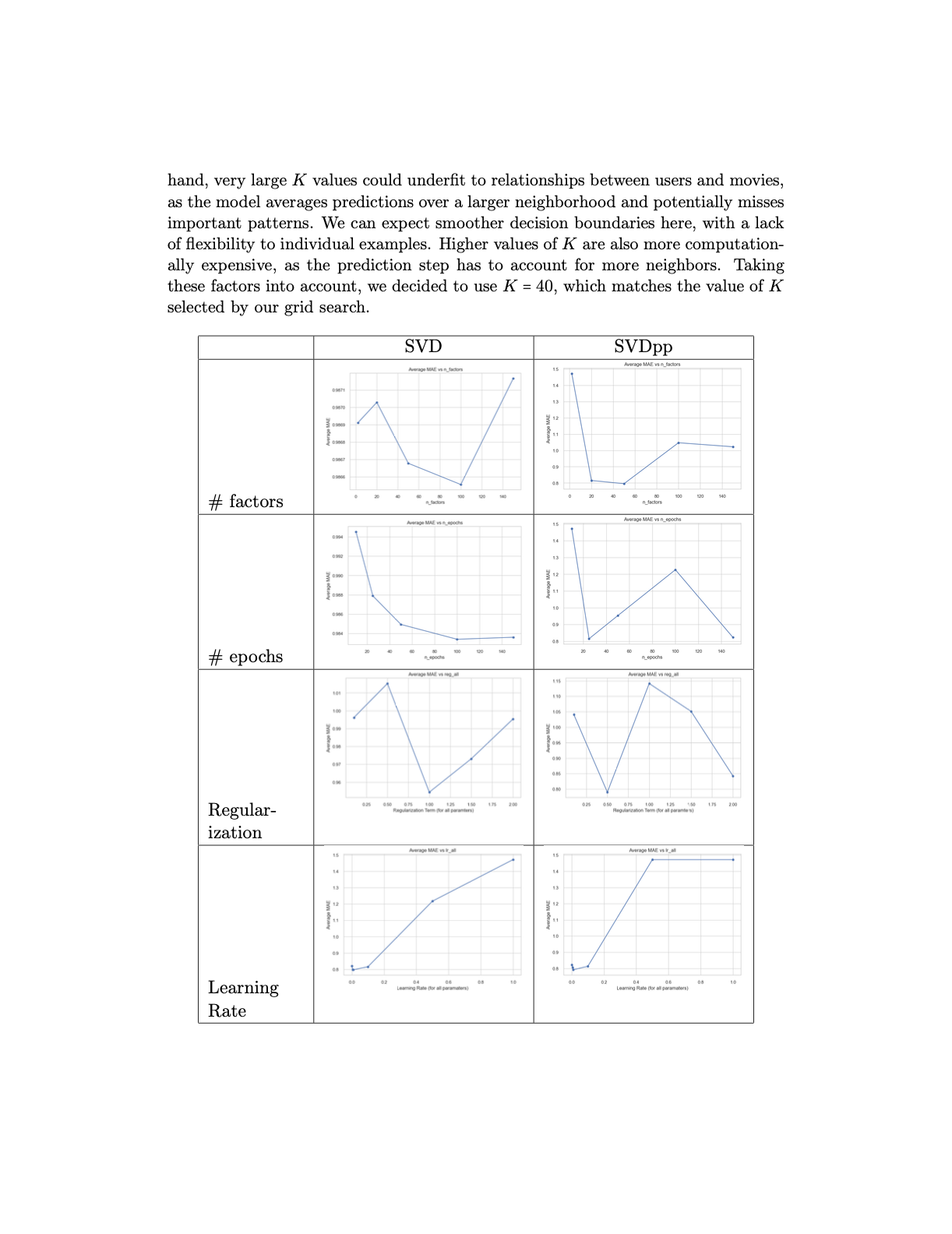
In order to solve this problem, my partner and I tested methods such as Collaborative Filtering, K Nearest Neighbor regression, and the famous SVD algorithm. We used tools such as Stochastic Gradient Descent and Autograd to fit our model. Ultimately, we landed on a hybrid endemble-based model that averaged rating predictions from three distinct models (KNN, SVD, and SVDpp) to reduce the overfitting that any individual model might exhibit. This gave us recommendation system that generalized well and performed competitively in our machine learning class leaderboard.
Our data comes from the MovieLens 100K data set, available on Kaggle, which was collected by the GroupLens Research Project at the University of Minnesota.
This data set consists of:
- 100,000 ratings (1-5) from 943 users on 1682 movies.
- Each user has rated at least 20 movies.
- Simple demographic info for the users (age, gender, occupation, zip)